
Parlar i interactuar amb les màquines en qualsevol idioma ha estat un dels objectius dels experts en tecnologies del llenguatge. No és nou, però cada vegada més aquest tipus de tecnologies s’està estenent a nivell d’usuari.
La nova generació de sistemes de reconeixement de la parla i també de processament del llenguatge natural ja han començat a arribar als usuaris a través de millores en els assistents personals (per exemple Apple Siri, Google Now, Microsoft Cortana) o mitjançant nous productes com el traductor de veu de Skype o l’altaveu intel·ligent Amazon Echo.

Fig 1: Esquema genèric d’una xarxa neuronal
El Deep Learning (els algoritmes que intenten reproduir les mecàniques del cervell humà en la codificació i descodificació de missatges i permeten l’autoaprenentatge), no és més que l’evolució de les clàssiques xarxes neuronals. Però el seu ús massiu sembla estar reinventant el desenvolupament i la investigació en diversos àmbits com el tractament de la imatge, el processament del llenguatge i les tecnologies de la parla. Les xarxes neuronals són sistemes d’aprenentatge que utilitzen unitats matemàtiques relativament senzilles, anomenades neurones, que treballen interconnectades, creant així diverses capes (veure Fig. 1). Aquestes capes permeten diferents nivells d’abstracció i, en certa manera, un aprenentatge més semblant a l’humà. Això contrasta amb les tècniques utilitzades fins el moment, com les estadístiques, on s’aprèn de les dades, igual que amb Deep Learning, però sense considerar abstraccions.
Les xarxes neuronals existeixen des dels anys 50, però ara funcionen
Una pregunta habitual és per què les xarxes neuronals artificials (una tècnica matemàtica que es remunta als anys 50) són ara tan populars. De fet, el 1969, Minsky & Papert van definir clarament les limitacions de les mateixes, incloent per una banda que les xarxes d’una sola capa són incapaces de computar la funció XOR entre dues condicions (el resultat és veritat només si una de les dues és veritat però no totes dues, ex. Joan és alt o baix); i, d’altra banda, que la capacitat computacional del moment no era suficient per processar xarxes neuronals de diverses capes. El problema de l’entrenament de la funció XOR es va solucionar amb l’algoritme de propagació inversa (Rumlelhart et al, 1986) i la capacitat computacional ha millorat enormement amb l’ús de les GPUs (Graphical Processing Units) que permeten fer centenars d’operacions alhora. Això sense oblidar que el 2006 es va assolir una fita important, que va marcar la introducció del concepte Deep Learning, quan es va aconseguir una manera efectiva d’entrenar xarxes neuronals molt profundes (és a dir, de diverses capes) (Hinton et al., 2006). Actualment, els algoritmes neuronals avancen amb tal rapidesa que les arquitectures particulars que avui són efectives podrien demà ser substituïdes en benefici d’altres, la qual cosa vol dir que parlem d’un camp en contínua evolució.
L’ús de Deep Learning en aplicacions de la parla
De forma natural, les xarxes neuronals s’han convertit en una eina per a l’aprenentatge automàtic. Així doncs, les arquitectures de múltiples capes amb varietat de tipologies de xarxes s’han utilitzat satisfactòriament per tècniques de classificació o predicció. Recentment aquest aprenentatge automàtic ha creuat fronteres i ha conquistat altres àrees, de manera que el reconeixement de veu o la traducció automàtica es poden plantejar com a problemes d’aprenentatge automàtic solucionables mitjançant determinades arquitectures neuronals. Vegem quines arquitectures neuronals han resultat efectives per camps de les tecnologies de la parla com el reconeixement de veu, la traducció automàtica i la síntesi de veu.
Reconeixement de veu i el seu salt de qualitat
En els últims anys, els algoritmes de Deep Learning han estat la clau per obtenir un salt molt significatiu en les prestacions dels sistemes de reconeixement automàtic de la parla. Les xarxes neuronals han mostrat ser una eina versàtil capaç de modelar tots els aspectes acústics, fonètics i lingüístics associats amb aquesta tasca. Els complexos sistemes tradicionals basats en una multitud de components específics han estat ja substituïts per estructures genèriques de gran versatilitat i millors prestacions. I any rere any segueixen apareixent noves arquitectures basades únicament en xarxes neuronals recurrents (Karparthy, 2014) amb millores significatives en la taxa d’encert.
Potser aquests nous sistemes no aportin coneixement sobre la complexitat del problema, però sí que han ajudat a resoldre-ho. Ara sabem construir màquines amb una capacitat sorprenent d’aprendre, a partir d’exemples, models tan complexos com els implicats en el reconeixement de la parla.
Traducció de text en un sol pas
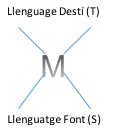
Fig. 2: Auto-codificador
La traducció de text mitjançant Deep Learning passa d’un llenguatge font a un llenguatge destí mitjançant una estructura d’auto-codificador (Cho, 2015) (veure Fig. 2): un codificador aprèn una representació (M) de les dades d’entrada (llenguatge font, S) per després descodificar-a dades de sortida (llenguatge destí, T). Aquest auto-codificador s’entrena amb textos traduïts. Les paraules font es mapegen a un espai reduït (veure Fig. 3). Aquesta operació permet reduir el vocabulari i aprofitar sinergies entre paraules similars (en termes morfològics, sintàctics i/o semàntics). Aquesta nova representació de paraules es codifica en un vector resum (una representació del llenguatge font que hem de descodificar al llenguatge destí) utilitzant una xarxa neuronal recurrent. Aquest tipus de xarxes té l’avantatge que ajuda a trobar les paraules més precises en funció del context. La descodificació es realitza seguint els passos inversos al codificador.
Recentment, s’han aplicat millores a aquesta arquitectura mitjançant un mecanisme d’atenció que permet utilitzar el context de la paraula que està sent traduïda en lloc d’utilitzar tota l’oració com a tal.
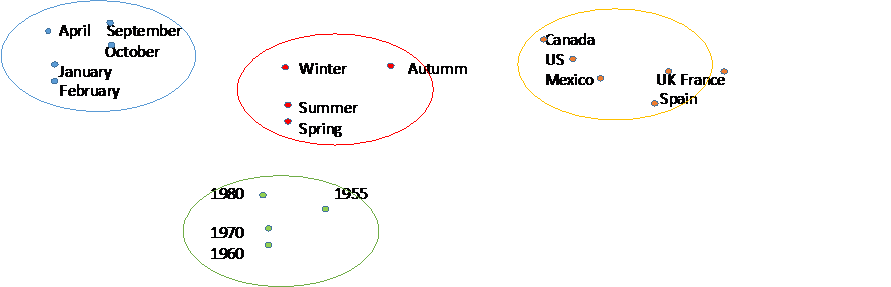
Fig. 3: Mapejat il·lustratiu de paraules
Síntesi de veu amb entonació natural en contextos llargs
En la síntesi de veu es transformen frases escrites en una de les possibles formes correctes de llegir-les. La tecnologia més madura fins ara concatena segments pregravats. No obstant això, en l’última dècada s’han fet avenços en síntesi estadística (tecnologia tradicional), que modela la veu mitjançant paràmetres que defineixin el discurs oral (per exemple, les pauses o l’entonació) i són apresos estadísticament. Donada una frase, se seleccionen els models adequats als seus fonemes i un algoritme de generació produeix el que finalment es transforma en veu. Una de les primeres aplicacions de Deep Learning ha estat generalitzar la definició dels contextos: en la síntesi estadística, es defineix un fonema precís segons el context. En canvi, a través de Deep Learning, és possible trobar els paràmetres adequats sense una definició explícita de contextos (Zen et al., 2013).
Recentment s’han utilitzat xarxes neuronals recurrents que modelen seqüències temporals: el propi sistema d’aprenentatge aprèn la continuïtat de la parla. Concretament, les xarxes recurrents denominades LSTM (long short-term memory) faciliten l’aprenentatge d’elements com l’entonació d’una pregunta o la lectura de frases relatives, que es produeixen en contextos de lectura llargs.
Tant els sistemes tradicionals estadístics com els actuals no fan una lectura que mostri encara la comprensió del text. Tots dos basen el seu aprenentatge en tres elements: algoritmes, dades i capacitat de càlcul. Els enormes avenços en tractament de Big Data, en capacitat per executar càlculs complexos i múltiples operacions simultànies obren noves perspectives per al Deep Learning. Augmentant les dades observables i la capacitat de càlcul, podrà aquest paradigma modelar els intricats processos mentals que utilitzem en la lectura?
El que queda per veure
Per als escèptics, els que van veure fracassar les xarxes neuronals en els 80 (precursores de l’actual Deep Learning) convé explicar que les millores aconseguides amb les noves tècniques neuronals ja s’han materialitzat en la qualitat dels sistemes de la parla i són revolucionàries (LeCun et al., 2015). Per exemple, en reconeixement de veu s’han aconseguit reduccions de la tasa d’error properes al 10% (veure TIMIT). A més, el fet que no calgui dissenyar les funcions que caracteritzen un problema, ja que s’aprenen automàticament, ha permès, només en el camp de les tecnologies de la parla, ampliar reptes, com són el reconeixement de veu end-to-end (aprèn una única funció que permet el pas directe de veu a text) (Hannun et al., 2014), traducció multilingüe (Firat et al., 2016) i multimodal (imatge i text) (Elliot et al., 2015).

D’esquerra a dreta: José A. R. Fonollosa, Marta R. Costa-jussà i Antonio Bonafonte.
Al Centre de Tecnologies del Llenguatge i de la Parla (TALP UPC) som pioners en el desenvolupament d’una línia d’investigació sobre la granularitat de caràcters (Costa-jussà & Fonollosa, 2016). Aquesta tècnica permet aprendre la traducció de text detectant subseqüències de paraules amb significat, com prefixos o sufixos, i reduint la grandària del vocabulari. Això aporta un alt nivell de generalització especialment per a llengües morfològicament flexibles, aportant un alt benefici en la qualitat de la traducció.
Pot ser que tornem a arribar a certs límits en les xarxes neuronals, però aquestes arquitectures ja han obert nous horitzons tant per a la investigació com per a un ampli ventall d’aplicacions, des del “simple” disseny d’una màquina capaç de vèncer en el popular joc japonès GO, fins el fort impacte que pot significar en sectors en creixement com la intel·ligència artificial (IA), internet of things (IoT), social computing, o el reconeixement d’imatge a més dels ja esmentats. Ens aboquem cap a la implementació de les xarxes neuronals en àmbits com la indústria aerospacial, l’educació, les finances, la defensa, l’e-commerce o la salut (diagnòstics, prescripció de medicaments). Afrontem novetats tecnològiques que amb tècniques clàssiques, com l’estadística, no han estat factibles o no han estat satisfactòriament abordables, raó per la qual sembla raonable pensar que els sistemes neuronals han vingut per quedar-se algun temps.
 T’uneixes?
Marta R. Costa-jussà, José A. R. Fonollosa i Antonio Bonafonte
Investigadors del Centre de Tecnologies i Aplicacions del Llenguatge i de la Parla (TALP UPC)